一、平台简介
“纪检智通”智能数据分析平台旨在为全国纪检监察机关和纪检监察干部提供便捷的数据分析工具,以大数据赋能正风反腐。该平台通过高效的数据采集、分析、挖掘与展示,提供全面、实时、精准的数据支持,能够自动构建问题发现模型并生成问题清单,加速问题识别和解决过程。利用智能化、低代码技术,平台降低了使用门槛,纪检监察干部可利用该工具轻松实现数据、人工智能模型与业务逻辑的无缝衔接,纵深推进工作开展。该平台不仅提高了工作质效,推动纪检监察工作规范化法治化正规化,提升数据驱动的治理能力和治理水平,助力纪检监察工作高质量发展。
二、研发背景
在当前纪检监察工作中,随着数据规模的不断扩大和业务需求的多样化,传统的数据管理和分析方法难以满足现有需求。纪检监察工作面临着信息来源广泛、数据量庞大、数据类型复杂等多重挑战。尽管数字化转型为纪检监察工作提供了巨大的潜力,但如何有效整合、清洗和挖掘数据背后的规律,仍然是亟待解决的问题。现有的理论研究和新兴技术未与纪检行业深度融合,难以支撑高效、精准的数据分析,主要面临三方面瓶颈,一是数据孤岛瓶颈导致不同系统之间的数据未能有效整合,无法实现信息共享与流通,严重影响决策效率和数据价值的发挥。二是数据清洗瓶颈由于数据来源复杂且格式多样,存在大量冗余、缺失或不一致的数据,人工清洗过程费时费力,且易出错,导致分析结果的准确性和可靠性受到影响。三是数据价值挖掘瓶颈则表现在现有的分析工具和数据挖掘软件存在使用门槛高、难度大、费用昂贵、功能单一等问题,无法充分挖掘数据背后的深层价值,限制了数据驱动决策的效果。为应对这些挑战,亟需一款能够整合数据、智能清洗、并高效挖掘数据价值的平台
。
为应对这些挑战,亟需构建一个能够整合数据、智能清洗,并高效分析数据背后规律的平台。该平台充分利用大数据和人工智能技术,针对纪检监察工作的不同需求场景,提供针对性、智能化的监督范式,精准发现问题,深度挖掘新型腐败和隐性腐败。
三、核心亮点功能
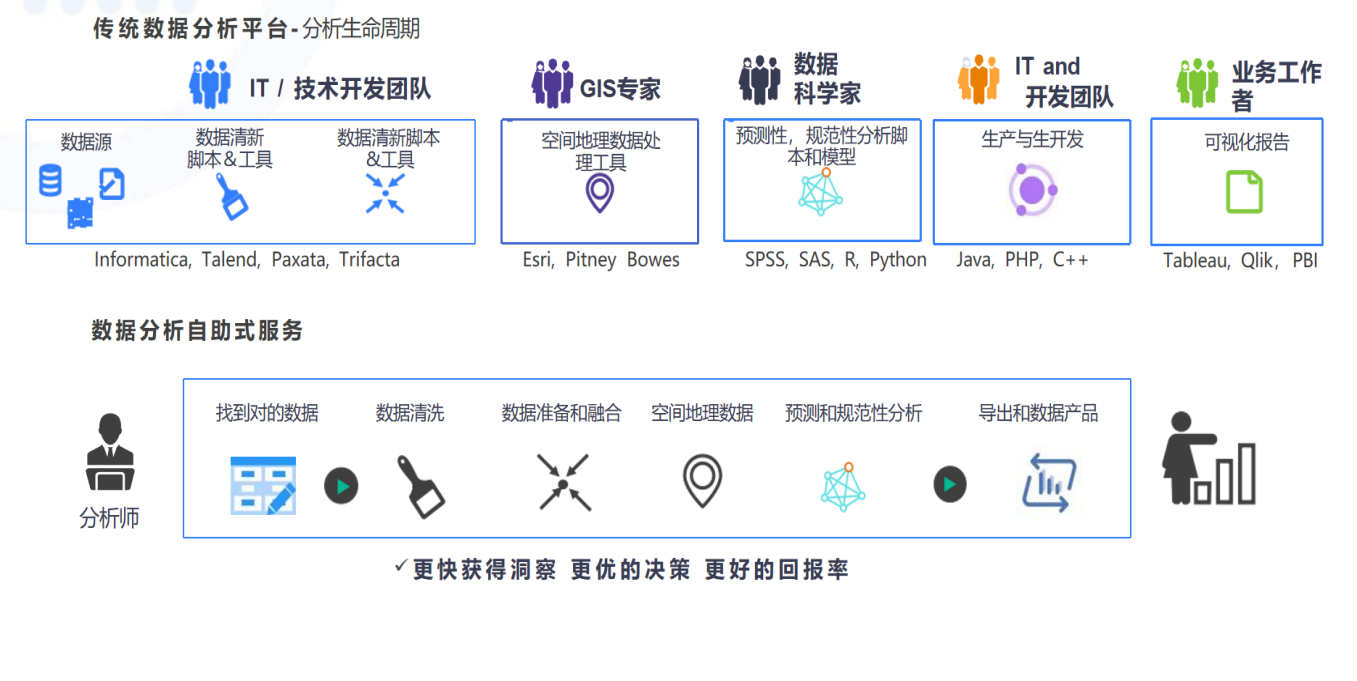
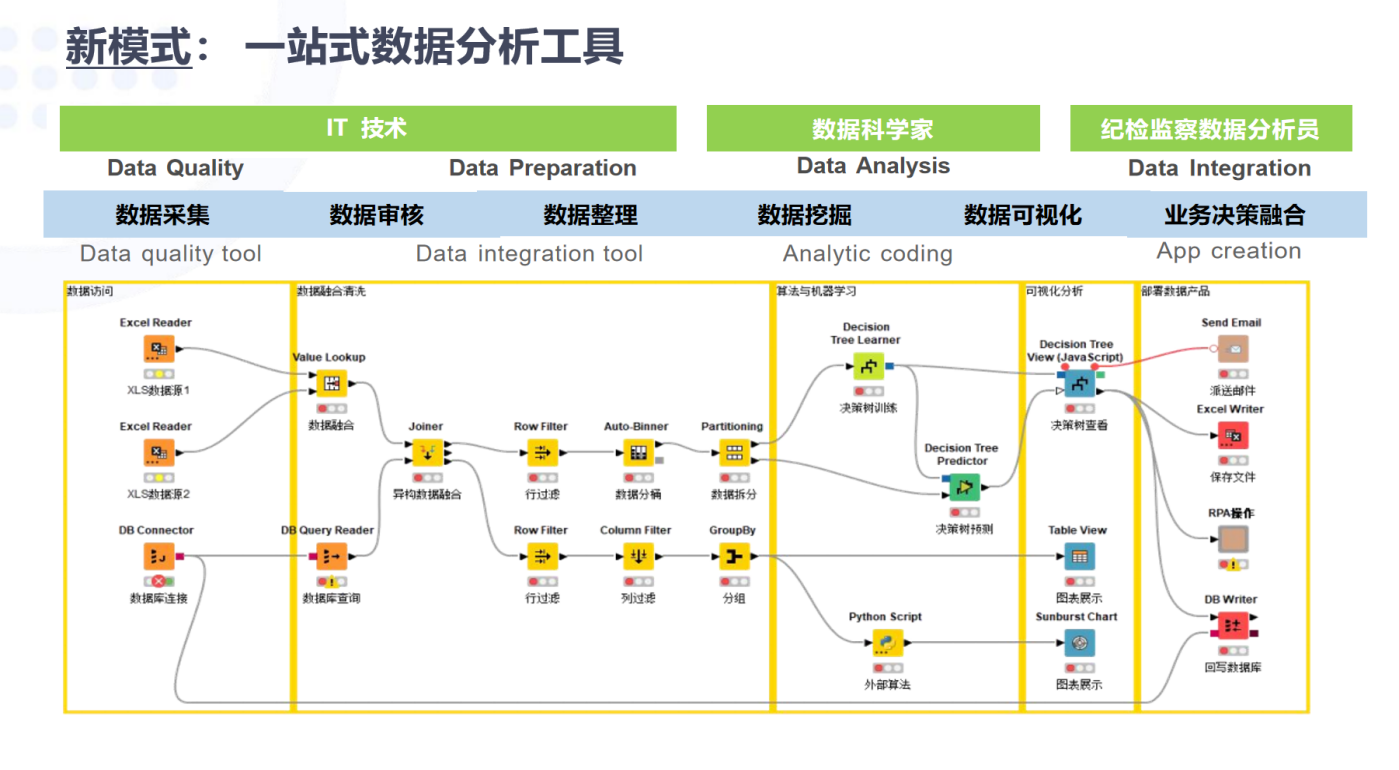
①新模式:一站式数据分析工具
全周期数据分析流程的自动化分析,能够在同一平台内实现从数据处理、数据清洗、数据分析、数据建模到数据展示与整合的全流程管理,确保高效、精准地进行数据处理和决策支持。
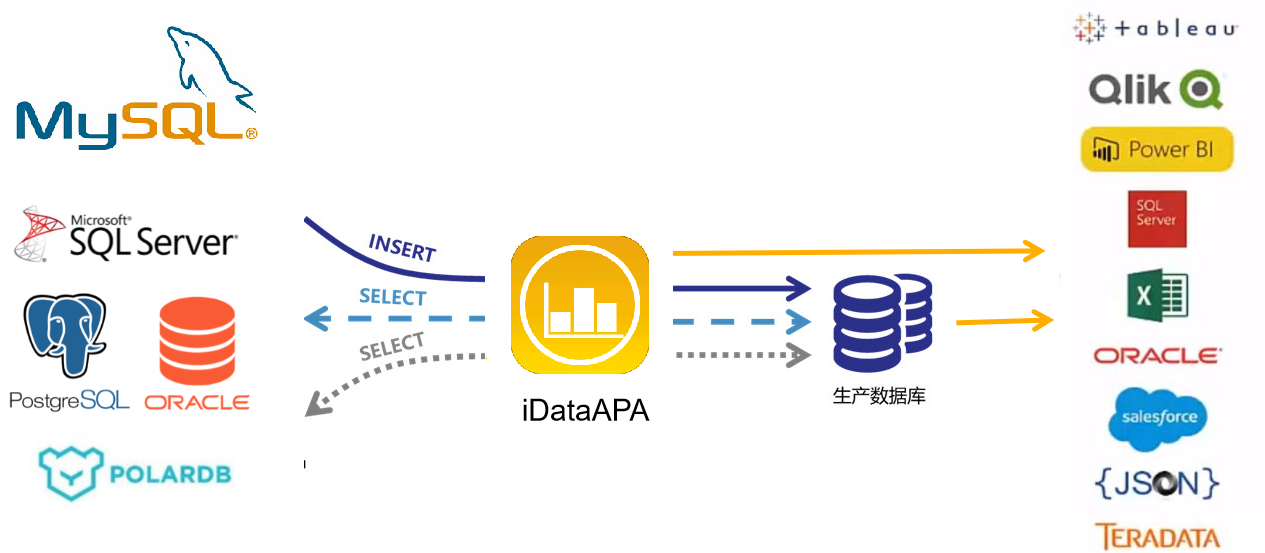
可以整合多种数据源,数据库参考构架模型为各种数据场景提供支持。
纪检智通涵盖整个数据分析生命周期,从数据收集到模型构建、评估再到报告生成。以下是纪检智通在数据分析生命周期中的主要功能:
数据收集:纪检智通可以连接多种数据源,包括数据库、Excel、文本文件、Web服务等,以便收集数据,确保能够全面获取监督相关数据。
数据清洗:纪检智通提供了一系列的数据转换和清洗工具,例如删除缺失值、去重、标准化等,帮助用户高效地处理和准备数据,确保数据质量。
数据探索:纪检智通支持多种数据可视化和交互式探索方法,例如直方图、散点图、箱形图等,帮助用户深入分析数据,发现潜在问题。
特征工程:纪检智通提供特征选择、变换和降维方法,例如主成分分析、线性判别分析等,帮助用户提取对监督和反腐工作有价值的特征。
模型构建:纪检智通支持多种机器学习算法和工具,如决策树、支持向量机、神经网络等,帮助用户建立有效的预测和分析模型,识别腐败风险和其他不正之风。
模型评估:纪检智通提供一系列模型评估工具,例如混淆矩阵、ROC曲线、精度、召回率等,帮助用户评估模型的性能,确保模型的准确性和有效性。
模型部署:纪检智通支持将训练好的模型导出成可部署的应用程序或Web服务,方便在实际监督工作中进行应用。
报告生成:纪检智通可以生成多种类型的报告,例如HTML、PDF、Excel等,以展示数据分析结果和发现,帮助纪检监察干部及时决策和采取行动。
纪检智通提供了完整的数据分析生命周期工具,帮助纪检监察干部从数据收集到模型构建、评估再到报告生成的整个过程,提高监督效率,强化反腐败工作。
②敏捷化:敏捷易用可视化,安全可信
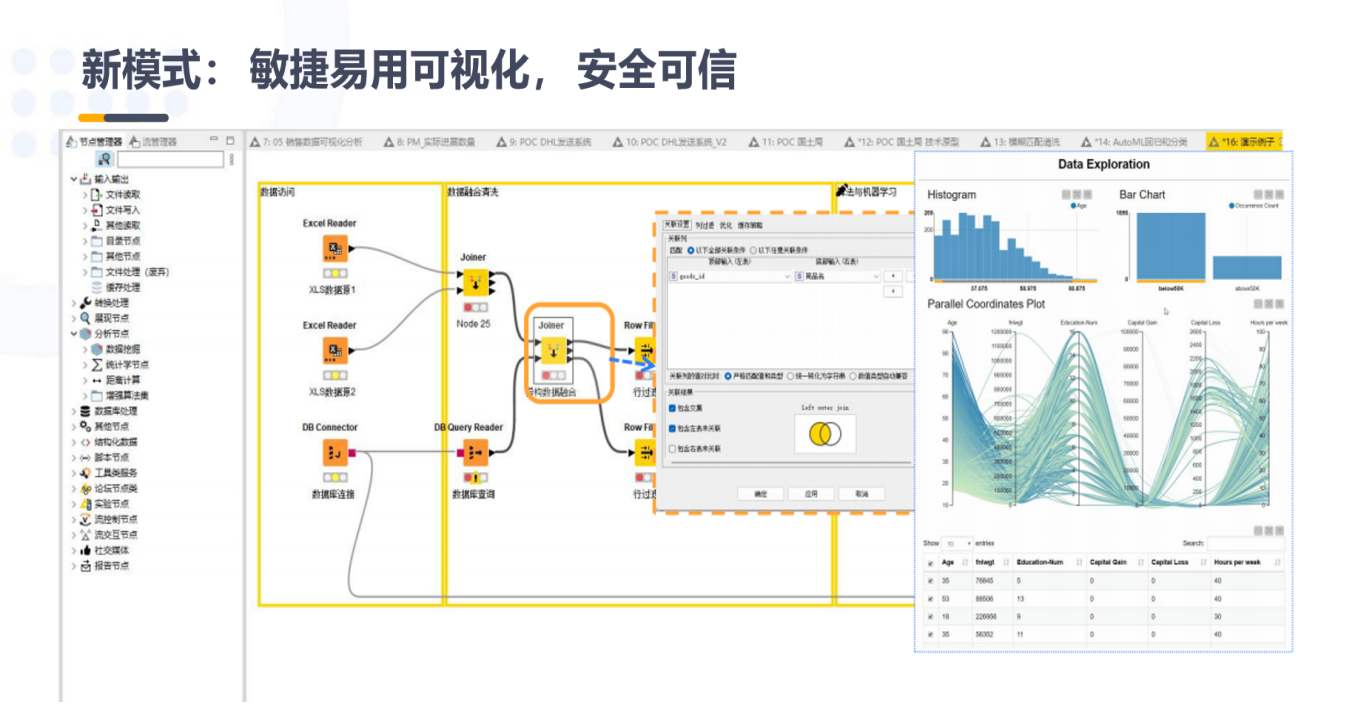
纪检智通作为一款面向纪检监察干部的数据与业务建模工具,提供了敏捷、易用的可视化分析功能,并确保数据分析过程的安全性和可信度。通过拖拽的方式,纪检智通使得数据分析和建模变得更加直观、便捷且易于理解。具体来说,纪检智通提供以下自助可视化数据建模的功能:
可视化界面:纪检智通提供图形化界面,用户可以通过简单的拖拽节点、连接节点来创建工作流程,无需编写代码,降低了使用门槛,使纪检监察干部能够快速上手并构建复杂的数据分析模型。
节点库:纪检智通拥有丰富的节点库,涵盖了数据处理、数据挖掘、机器学习、统计分析、文本分析等多个领域,支持从数据清洗到腐败识别、风险评估等多个数据分析任务,帮助纪检监察干部深入分析相关数据。
可重复性:纪检智通确保数据建模和分析过程的可重复性。可以记录、保存并分享他们的工作流程,确保数据分析的准确性和可靠性,便于后续检查与复现分析结果,强化监督透明度。
自动化:纪检智通提供了自动化的数据处理和建模功能,大大节省了用户的时间和精力。自动化流程不仅提升了分析效率,还能够提高处理数据的速度和精度,快速响应反腐和监督需求。
效率工具:纪检智通提供快捷工具和功能,帮助用户更高效地完成数据分析任务。通过智能化功能,纪检智通助力纪检监察干部优化工作流程、快速发现问题,提升工作效能。
纪检智通作为一款自助可视化数据建模工具,具备敏捷、易用、自动化和高效等特点,使数据分析工作更加便捷、准确且高效。纪检监察干部通过图形化界面和丰富的节点库可以轻松构建数据分析流程,并确保结果的可重复性和可靠性,进一步提高监督工作的智能化水平。
③模块化:可以封装和共享业务模型
纪检智通不仅支持自助可视化数据建模,还支持用户将自己设计的业务处理流封装成可复用组件,并共享给其他用户使用。这些封装的组件,称为节点,能够进一步提升工作流的效率和灵活性。
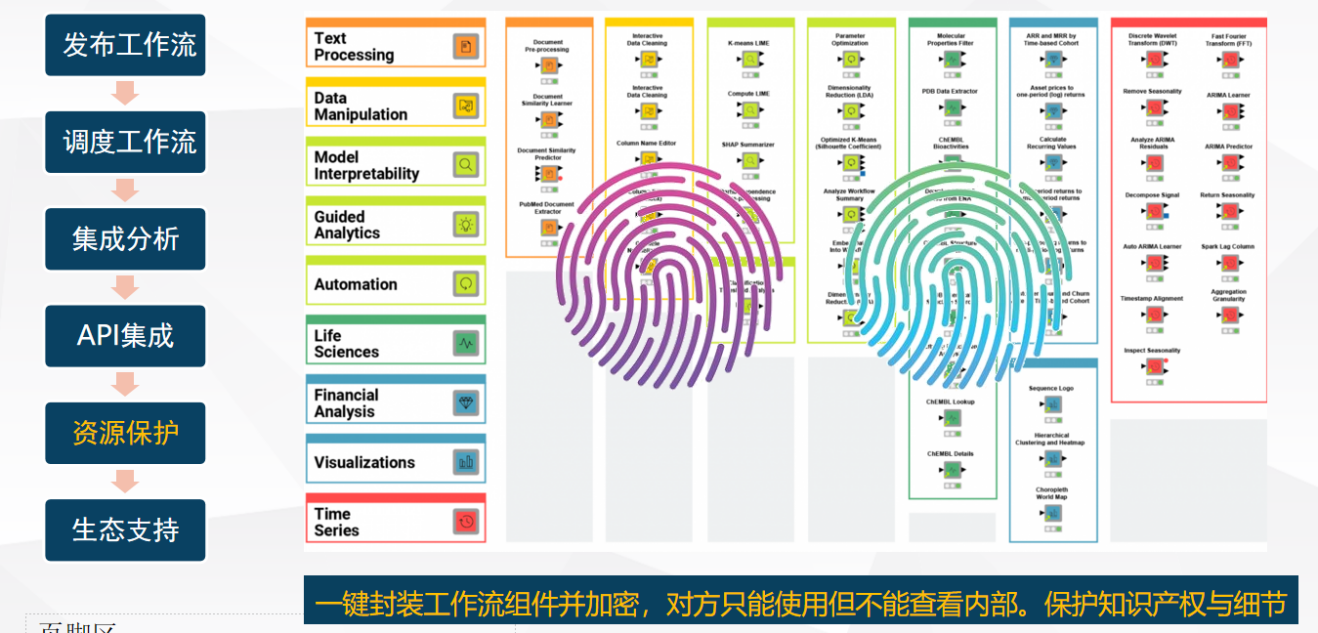
可视化封装与共享:纪检智通允许用户将一系列数据分析操作封装成一个节点(组件)。这些组件可以通过可视化方式创建和编辑,并可以被轻松添加到工作流程中,以实现数据分析自动化。封装的节点不仅增强了工作流程的灵活性,还能在不同的监督场景下反复使用。
加密与授权管理:为了确保敏感信息的安全性,纪检智通的封装组件支持密码加密功能。用户在使用这些封装组件时,需要提供密码才能解密其中的敏感信息或执行需要授权的操作。此加密功能在以下场景中特别有用:
数据隐私保护:封装的组件中可能包含敏感数据,如数据库连接密码、API密钥等。为了避免敏感信息的泄露,纪检智通支持对这些数据进行加密处理,确保数据隐私安全。
授权管理:某些封装组件可能需要执行特定操作,例如从外部平台获取数据或定时执行任务。通过加密和设置密码,纪检智通实现了更精细的授权管理,确保只有授权用户才能执行这些操作。
纪检智通通过封装数据分析组件并加密敏感信息,不仅提高了数据分析过程的安全性,还增强了工作流程的灵活性和可重复使用性。纪检监察干部可以通过封装和共享组件,优化监督工作流程,提升效率,同时保障数据隐私和信息安全。
④一体化: 数据处理流内置AI组件
纪检智通在设计数据分析与处理流程时,采用了一体化的思路,将人工智能(AI)技术深度融合于数据分析流程中。通过内置AI组件,尤其是大语言模型(LLM)技术的引入,纪检智通不仅提升了数据处理效率,还增强了数据分析的智能化水平,使得纪检监察干部在处理监督数据时能够更加精准、高效。
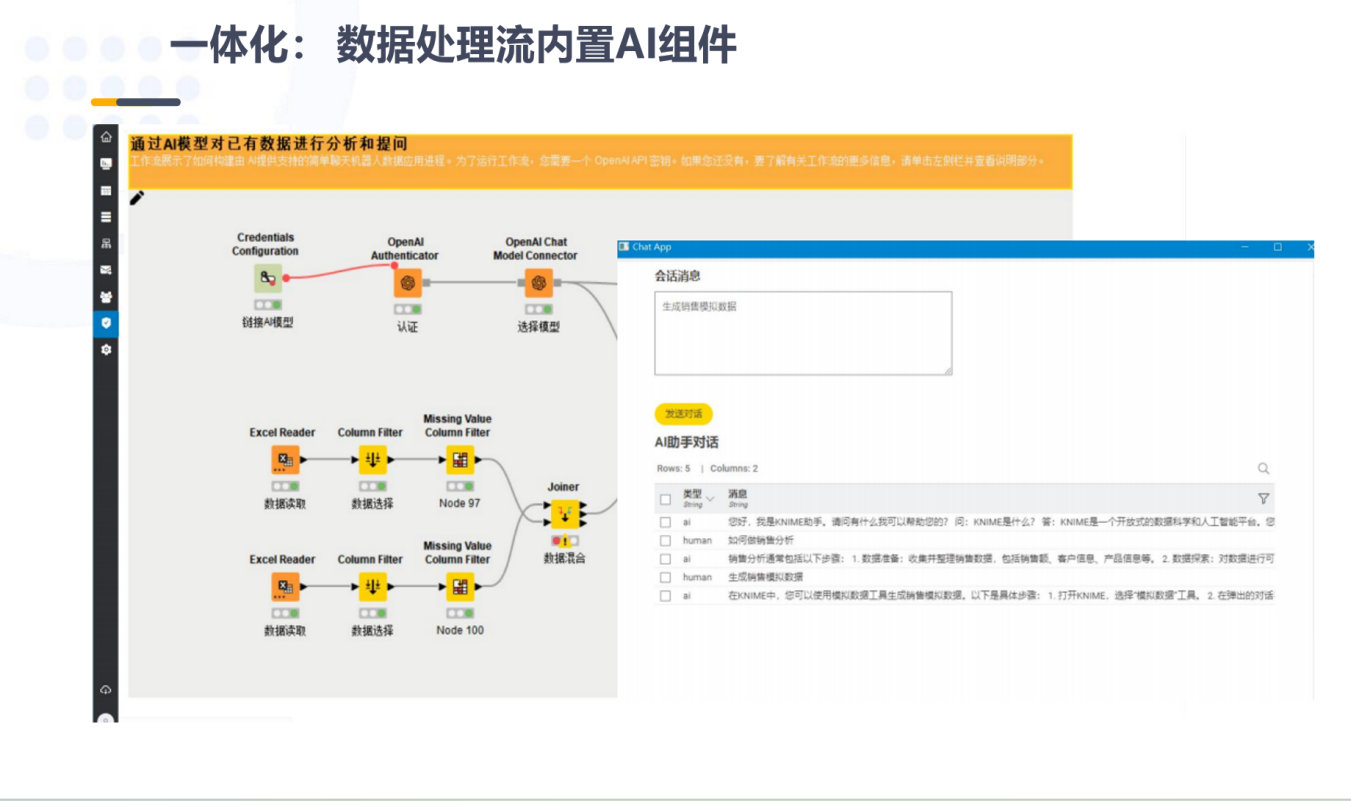
AI驱动的数据处理流:纪检智通将AI技术嵌入到数据处理流的各个环节,从数据清洗、特征提取到建模分析等,都可通过AI自动化完成。内置的AI算法能够根据监督工作中常见的场景和需求,自动选择合适的分析方法并处理数据,极大地减轻了用户的手动操作负担,提升了数据处理的效率和智能化水平。
智能化的数据清洗:数据清洗是监督数据分析中的重要环节,传统的数据清洗往往需要大量的人工干预,而纪检智通的AI组件可以自动识别和处理缺失数据、异常值、重复数据等问题。通过机器学习模型,纪检智通能够不断优化数据清洗策略,提高数据质量,为后续的分析提供准确可靠的基础。
自动化特征提取与选择:纪检智通的AI组件能够智能地从海量数据中提取出关键特征,并根据特征之间的相关性自动选择最具预测性的特征。这一过程不仅节省了人工选取特征的时间,还提高了分析模型的准确性,为腐败风险识别、问题预警等提供了更加精准的数据支持。
纪检智通通过一体化的数据处理流和内置AI、大语言模型组件,为纪检监察干部提供了一个全方位的数据分析平台。AI技术自动化的数据处理、智能化的文本分析、大语言模型的深度理解能力,帮助纪检监察干部从海量数据中提取有价值的信息、识别潜在问题,并提前做出精准的决策。
四、案例说明
死亡人口领取农村离任“两委”主干生活补贴模型构建步骤:
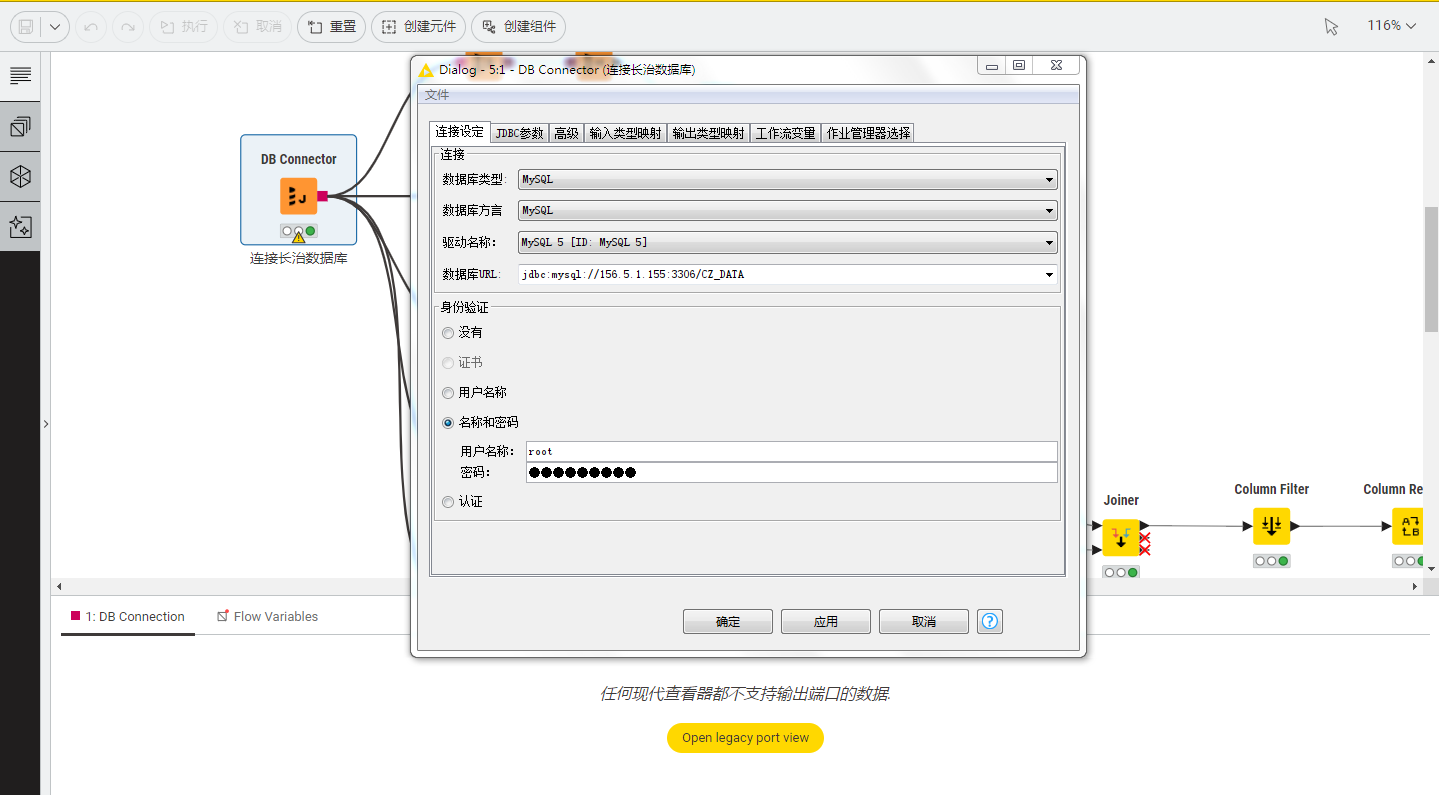
第1步,配置数据库,填写用户名、密码、IP地址。
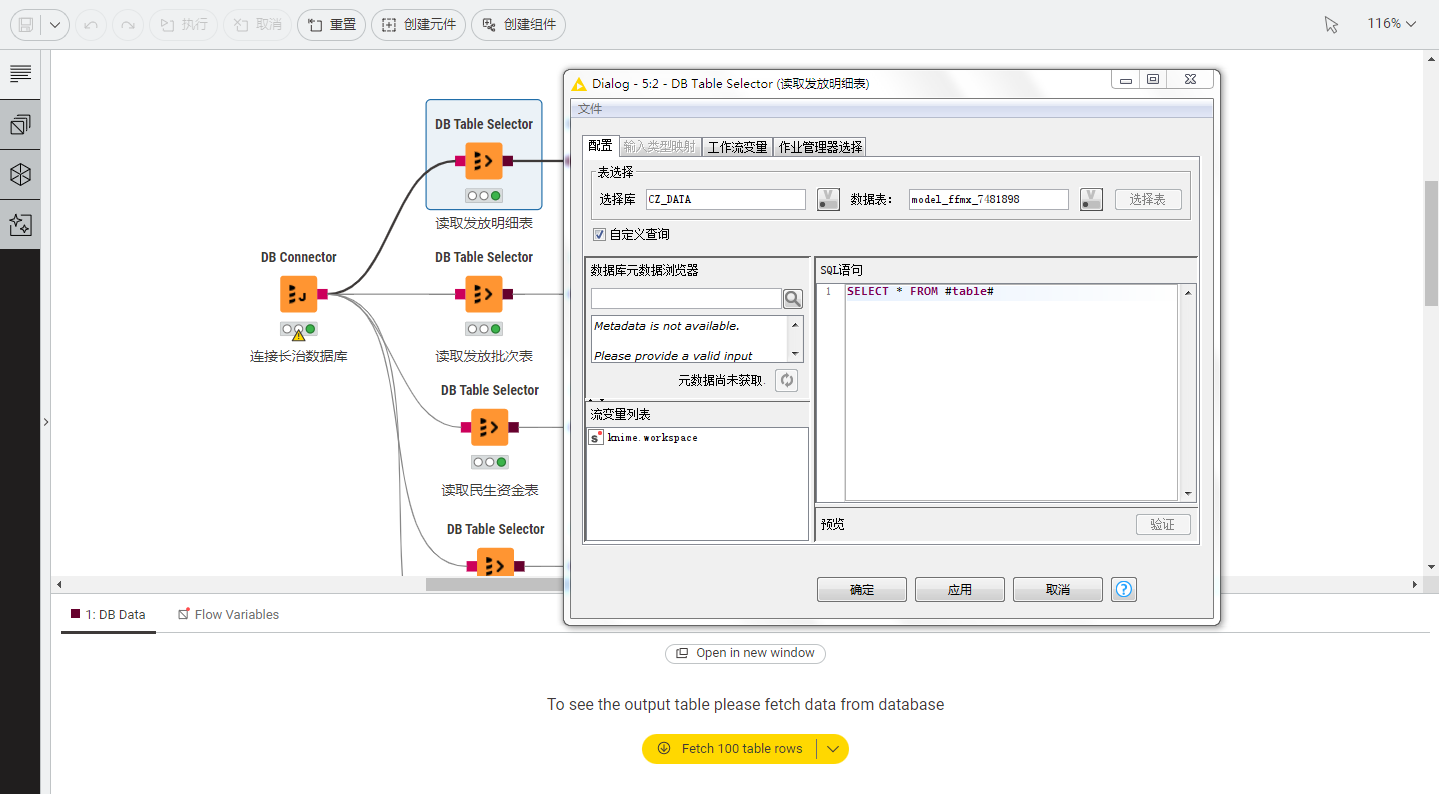
第2步,选择数据表并读取数据。
第3步,根据关联字段,把多个数据表合并成新的数据表。

第4步,在新的数据表中,筛选出需要展示的字段。

第5步,把英文字段映射成中文字段。

第6步,按照资金项目分组并挑选要分析的资金项目。


第7步,选择并读取死亡人口数据。

第8步,调整死亡日期格式。

第9步,根据政策文件、补贴发放对象、发放标准等条件,进行关联碰撞分析。
第10步,条件限制,判断死亡日期和补贴发放日期,生成预警数据。


